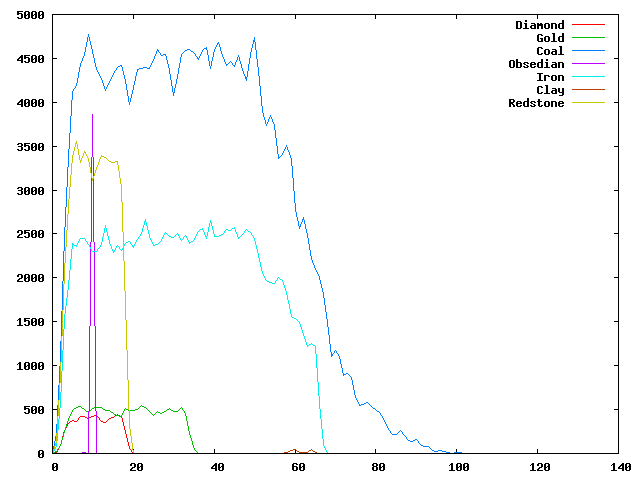
I have been playing Minecraft a lot lately, and I was wondering where to dig for certain minerals. I knew Redstone was only found in lower layers of the level, but I knew nothing concrete.
I pulled together Gnuplot and a Python lib for reading NBT files and analyzed a level. Here is the result, the code and some notes.
I suspect the sea level is around 60, because of the clay there. Coals is rare and Iron very rare above sea level.
Both Diamond and Redstone stop at 20, while gold can be found a little higher. There is no noticeable decline in Coal and Iron near the bottom, so best is to dig below level 20.
As can be seen above, there is a lot of Lava, Water and Obsidian around and below level 10, so stay above level 10 for safe mining.
The code:
fromnbtimportnbtfromitertoolsimportizip_longest,repeatimportglobimportGnuplotfiles=glob.glob("/Users/pepijndevos/Library/Application Support/minecraft/saves/World2/*/*/*.dat")output="minecraft.png"col=[]forfileinfiles:printfilefile=nbt.NBTFile(file,'rb')col.extend(izip_longest(*[iter(file["Level"]["Blocks"].value)]*128))file.file.close()layers=zip(*col)minerals={#'Bedrock': '\x07',
#'Water': '\x09',
#'Lava': '\x0B',
#'Sand': '\x0C',
#'Gravel': '\x0D',
'Gold':'\x0E','Iron':'\x0F','Coal':'\x10','Obsedian':'\x31','Diamond':'\x38','Redstone':'\x49','Clay':'\x52',}names=minerals.keys()hexes=minerals.values()defcount_minerals(layer):deffilter_mineral(mineral):count=len([blockforblockinlayerifblock==mineral])returncountm=map(filter_mineral,hexes)returnmg=Gnuplot.Gnuplot(debug=1)g('set term png')g('set out "%s"'%output)g('set style data lines')data=zip(*(count_minerals(layer)forlayerinlayers))data=(Gnuplot.PlotItems.Data(list(enumerate(mineral)),title=names[index])forindex,mineralinenumerate(data))g.plot(*data)
I regret doing this thing in Python. My coding style is strongly influenced by Clojure, and I had to do a number of hacks that would be trivial to do in Clojure. I might do a comparison in a future post if I ever do a Clojure version.
Yesterday I had the idea of lazy sequences that can go in both directions. I dropped into #clojure on irc.freenode.net to ask someone about it.
Given the fact that Clojure-in-Clojure is possible, it is thus possible to define lazy seqs. Would it also be possible to define a lazy seq where the 0th element is actually in the middle of an infinite lazy seq extending in both ways? so like (iterate inc) with negative number included :)
I found Chris Houser(Author of Joy of Clojure) interested, and willing to help me along.
so... how shall we proceed? You want to see my code or should I try to drop hints or ask leading questions?
I went for the later one, and had a great learning experience. Near then end Paul deGrandis chimed in to recommend Joy of Clojure. I'm convinced!
Joy of Clojure has an awesome section on proxy, reify, defprotocol, and defrecord. I reference it often to judge if I'm abusing something
At the point you're at in Clojure (based on what I follow in here), you'd get a lot of mileage out of it.
(defprotocolSpinnable(spin[this]"Return a seq walking the opposite direction as this"))(defniter-bi[xfb](reifySpinnable(spin[_](iter-bixbf))clojure.lang.ISeq(first[_]x)(more[_](iter-bi(fx)fb))(next[this](restthis)); same as rest since all iter-bi's are infinite seqs(seq[this]this)(equiv[__]false))); cheater!(extend-typeclojure.lang.LazySeqSpinnable(spin[this](spin(seqthis))))(->>(iter-bi0incdec)(drop4)spin(take10));=> (5 4 3 2 1 0 -1 -2 -3 -4)
fliebel: Given the fact that Clojure-in-Clojure is possible, it is thus possible to define lazy seqs. Would it also be possible to define a lazy seq where the 0th element is actually in the middle of an infinite lazy seq extending in both ways? so like (iterate inc) with negative number included :)
chouser: ISeq only provides an API for walking forwards. You'd need a different interface for walking the other direction.
fliebel: Hrm :( that means I'll be unable to use with with existing functions, right?
chouser: well, what existing function do you intend to call to get item before 'first'?
fliebel: Dunno‚ I mean, if I'm not using ISeq, I can’t even use first, right?
chouser: well, your theoretical bidirectional lazy seq could implement ISeq for going forward
fliebel: Oh wait, Java, so I can implement ISeq and add my own interface and fns for going the other way.
fliebel: How about this‚ you define a lazy seq like iterate but with 2 fns, for going in either direction. then you call spin on it to change which direction you're seqing over :)
chouser: hm, interesting.
fliebel: So, what Clojure bits do I need to implement that?
chouser: a deftype and ... a function?
fliebel: *looks up deftype*
chouser: actually, just a deftype would do, though it's not quite as pretty.
chouser: I think that's the same as what I have. but you said "nearly"?
fliebel: The problem I had was that first was defined as the first of this, but I couldn't do (first this) of course.
chouser: if you want to "check" your answer:
(defprotocolSpinnable(spin[this]"Return a seq walking the opposite direction as this"))(defniter-bi[xfb](reifySpinnable(spin[_](iter-bixbf))clojure.lang.ISeq(first[_]x)(more[_](iter-bi(fx)fb))(next[this](restthis)); same as rest since all iter-bi's are infinite seqs(seq[this]this)(equiv[__]false))); cheater!(extend-typeclojure.lang.LazySeqSpinnable(spin[this](spin(seqthis))))(->>(iter-bi0incdec)(drop4)spin(take10));=> (5 4 3 2 1 0 -1 -2 -3 -4)
fliebel: this is your version?
chouser: yep
fliebel: very close :) Only you have equiv defined and next uses more. Does it matter if you use (.more method call) or rest?
chouser: not really. yours is probably faster
but duplicates half a line of code. :-)
fliebel: yea... :(
chouser: so take your pick. what you've got is good.
fliebel: One problem I have is that drop 5 returns a lazy seq which I can't reverse.
chouser: yeah, you see how I work around that in my example?
fliebel: rest, I used seq to do the job
chouser: oh! smart!
chouser: interesting -- I hadn't considered that, and wouldn't have been sure it would work. nicely done.
fliebel: I wasn’t sure it would work, but seq is magic you know...
fliebel: One thing I haven't figured out yet is how to make a seq that goes 1 2 3 4 5 4 3 2 1, so changes direction in the middle.
chouser: BTW, I wanted to call attention to my comment on rseq. I think we're abusing it here and probably ought to define a new protocol instead. (defprotocol Spinnable (spin [_])) or something.
fliebel: Okay. that simple?
chouser: yep
fliebel: So now in reify I replace reversible with spinnable?
chouser: there, now you don't have to call seq manually on lazy-seqs:
(defprotocolSpinnable(spin[this]"Return a seq walking the opposite direction as this"))(defniter-bi[xfb](reifySpinnable(spin[_](iter-bixbf))clojure.lang.ISeq(first[_]x)(more[_](iter-bi(fx)fb))(next[this](restthis)); same as rest since all iter-bi's are infinite seqs(seq[this]this)(equiv[__]false))); cheater!(extend-typeclojure.lang.LazySeqSpinnable(spin[this](spin(seqthis))))(->>(iter-bi0incdec)(drop4)spin(take10));=> (5 4 3 2 1 0 -1 -2 -3 -4)
fliebel: What? You can just add behavior to existing types? Am I in #ruby?
chouser: nope. in clojure we do it without monkey patching or adapter classes. :-)
chouser: I mean "nope" you're not in #ruby. Of course you can write new functions that take existing classes as args that then do their own thing with them.
fliebel: But you just added extra behavior to LazySeq, right?
dnolen: it's a properly namespaced extension tho. It's not visible to other namespaces.
chouser: it certainly looks like I did. In this case we could have written spin like: (defn spin [x] (if (instance? LazySeq x) ...))) right?
fliebel: I think so...
chouser: it's our function, we just defined it with defprotocol which allows us to add new cases on the fly
fliebel: yay
chouser: essentially. Except then rhickey sprinkled it with magic dust to make it very fast.
fliebel: :)
chouser: it's good to know not everyone knows about this yet -- it's my topic at Strange Loop
fliebel: oh, I feel special now :)
chouser: good I'm glad! But... why?
fliebel: Because I know something not everyone knows ;)
chouser: ah, good!
fliebel: Except that I'm not o sure yet what exactly you just said. Only that it's magic and fast. Two things I like especially.
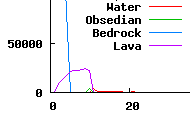 As can be seen above, there is a lot of Lava, Water and Obsidian around and below level 10, so stay above level 10 for safe mining.
As can be seen above, there is a lot of Lava, Water and Obsidian around and below level 10, so stay above level 10 for safe mining.