I’m currently developing Mosaic, a schematic editor built on web technology. In the process of adding online collaboration, I wrote a library to help me manage and synchronize state. The library is called Hipflask.
In my previous post I wrote about different strategies for dealing with conflicts when multiple users are editing the same object. In this post I want to focus more on the library I wrote to manage state.
Hipflask is basically a ClojureScript/Reagent atom backed by PouchDB.
Mosaic is written in Reagent, a ClojureScript React wrapper. The fundamental building block of Reagent is the Ratom (Reagent atom), a data structure that allows atomic updates by applying functions to its state. It then monitors state updates, and redraws components that depend on the Ratom. It’s quite elegant.
The semantics of a Clojure atom (after which ClojureScript and Reagent atoms are modelled) is that there is a compare-and-set! function that atomically updates the state if the expected old state matches the current state. swap! is a wrapper over that which repeatedly applies a function until it succeeds.
The neat thing is that CouchDB update semantics are exactly like compare-and-set!. You update a document, and if the revision matches it succeeds, if there is a conflict the update is rejected. You can layer swap! behavior on top of that which applies a function to a document repeatedly until there is no conflict.
So what you get if you combine PouchDB with a Ratom is that you can apply functions to your state, which will resolve database conflicts and rerender your app. The PouchDB atom even listens for database changes, so that remote changes will update the cache and components in your app that depend on it.
Basically it transparently applies functions to the database and updates your UI on database changes.
One thing that sets Hipflask apart from my previous CouchDB atom is that it manages a prefix of keys. This plays well with sharding, so you can have a PouchDB atom containing all foo:* documents. Worth noting is that it’s only atomic per document, and assumes the first argument to your update function is a key or collection of keys that will be updated.
You can use Hipflask in two main ways. The first way is offline first. The atom is backed by a local PouchDB which can by replicated to a central database. This way the app remains fully functional offline but replication conflicts are not handled automatically. You can also make it talk directly to a central CouchDB, in which case it does not work offline but conflicts in the central database are resolved automatically.
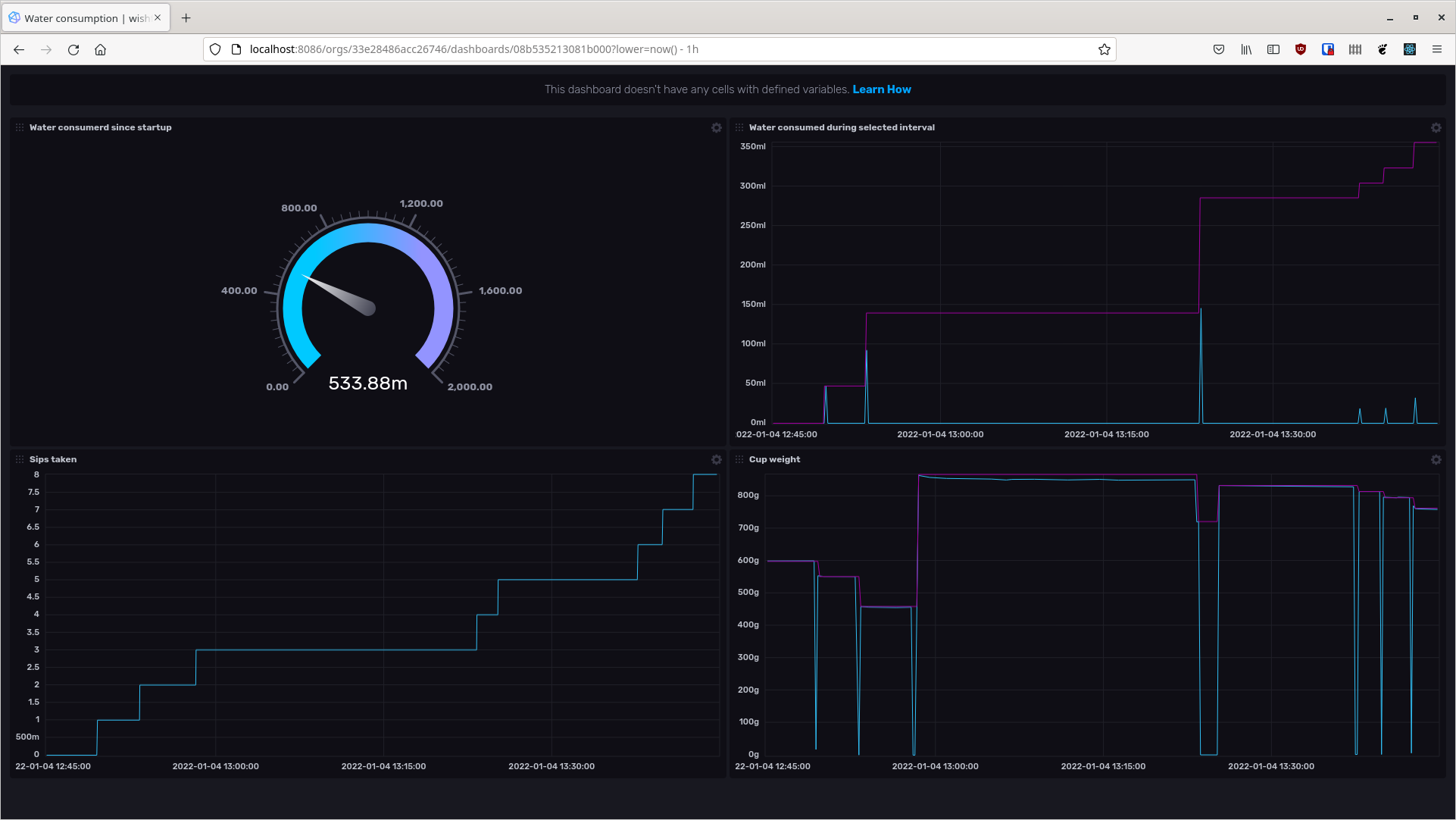
As a demo of the library, I made a Global Cookie Clicker app. It’s an offline-first collaborative cookie clicker. You can click cookies offline, and they are then synchronized to a central CouchDB. The entire code is less than 70 lines.
It basically defines a PouchDB atom
(def db (hf/pouchdb "cookies"))
(def rginger (r/atom {}))
(def ginger (hf/pouch-atom db "gingerbread" rginger))
And then when you click the button it calls this function that increments your cookie document.
(defn make-cookie [a n _]
(swap! a update-in [(str (.-group a) hf/sep me) :cookies] #(+ % n)))
This library has been very useful in building Mosaic, and I hope it is useful to others as well.